
Artigos Técnicos
Análise de Subsistemas Avançados de Armazenamento
![]()
2 – Interfaces à disco
Uma vez entendidos alguns dos aspectos importantes das unidades de disco rígido (ver Cap.1 – Discos Rígidos), conforme utilizadas atualmente nos modernos subsistemas de armazenamento, podemos, agora, analisar suas interfaces.
O termo interface neste capítulo refere-se ao tipo de conectividade utilizado para acessar os discos. Os principais fabricantes do mercado “High-End” utilizam 3 tipos de conexão, a saber: “SMALL COMPUTER SYSTEM INTERFACE” (SCSI), “FIBRE CHANNEL – ARBITRATED LOOP” (FC-AL) e SERIAL STORAGE ARCHITECTURE (SSA). Apesar de haver várias outras opções de conectividade, até o momento em que este documento esta sendo escrito, não há informações de estarem sendo utilizados em quaisquer subsistemas que atendam o ambiente MainFrame IBM.
Estas interfaces conectam os discos rígidos de um subsistema às suas placas adaptadoras de disco (“DISK ADAPTERS” – DAs), as quais recebem nomes distintos nos equipamentos de alguns fabricantes (ACPs para HDS Lightning 9900V series, SSA ADAPTER para IBM Shark 2105 800T, DAs para EMC Symmetrix 5.5 e DMX, p.ex.), mas sempre cumprindo a mesma função; interligar os circuitos internos de CACHE aos discos do subsistema.
Perfeitamente adaptados às suas funções, os protocolos de interface a disco apresentam características operacionais que influenciam em maior ou menor grau o desempenho final dos volumes.
A sigla SCSI refere-se simultaneamente a um conjunto de padrões ANSI de arquiteturas físicas de interfaces, e ao protocolo utilizado nesta forma de conexão.
Suas várias definições evoluíram ao longo dos anos, chegando hoje a 10 padrões distintos (veja figura abaixo).
|
Tecnologia |
Comprimento Max. Conexão (metros) |
Velocidade Máxima (MBps) |
Número Máximo De Devices |
|
SCSI-1 |
6 |
5 |
8 |
|
SCSI-2 |
6 |
5-10 |
8 ou 16 |
|
Fast SCSI-2 |
3 |
10-20 |
8 |
|
Wide SCSI-2 |
3 |
20 |
16 |
|
Fast Wide SCSI-2 |
3 |
20 |
16 |
|
Ultra SCSI-3, 8-bit |
1.5 |
20 |
8 |
|
Ultra SCSI-3, 16-bit |
1.5 |
40 |
16 |
|
Ultra-2 SCSI |
1.5 |
40 |
8 |
|
Wide Ultra-2 SCSI |
12 |
80 |
16 |
|
Ultra 160/Ultra 4 |
12 |
160 |
16 |
Figura 5. Tipos de interface SCSI
Em todos os casos, a interface SCSI compõe-se de um barramento de dados (de 8 ou 16 bits) e linhas de sinal para identificação de operações e status. As principais diferenças entre um tipo de SCSI e outro ficam por conta da largura do barramento de dados e da velocidade de “clock” utilizada. Cada dispositivo conectado a uma dada interface SCSI recebe um identificador (“SCSI-ID”), que corresponde a um bit do barramento de dados (de onde se concluí que o suporte a 8 ou 16 dispositivos fica por conta desta mesma largura de barramento).
As operações sempre acontecem entre um “INITIATOR” e um “TARGET”, ou seja, são sempre ponto-a-ponto. No padrão SCSI, enquanto um par esta em comunicação, todos os outros dispositivos tem de aguardar sua vez. Uma vez concluída a comunicação corrente, os outros dispositivos podem iniciar o que é conhecido como arbitragem, ou seja, ativam os bits correspondentes aos seus identificadores, no barramento de dados, como forma de indicar uma operação pendente. O dispositivo com o MAIOR SCSI-ID vence (maior prioridade) e inicia a transmissão de dados, monopolizando, durante este tempo, todo o barramento.
Basicamente, arbitrar significa verificar se há, no barramento de dados, qualquer bit presente, de valor maior do que o do próprio dispositivo. Caso haja, o dispositivo tentando a arbitragem perde e tem de aguardar o próximo ciclo.
Nos grandes subsistemas, a placa adaptadora é definida como INITIATOR, e os discos como TARGETs. Uma vez vencida a arbitragem, o dispositivo inicia os ciclos de barramento, utilizando combinações das linhas de sinal (“BSY”, “SEL”, “REQ” e “ATN”), conforme descrição abaixo :
Nota : para iniciar a fase de arbitragem, os dispositivos devem aguardar que o barramento esteja na situação de “BUS FREE” por um tempo pré-determinado, (aprox. 800 nS), chamado de “bus settle delay”. Isto é devido a um fenômeno conhecido como “wire-OR glitch”, que pode fazer com que o sinal de BSY pareça falso, mesmo tendo sido ativado como verdadeiro.
Uma vez obtido o controle sobre o barramento, entra-se no que é chamado coletivamente de “INFORMATION TRANSFER PHASES (COMMAND, DATA, STATUS & MESSAGE)”. Conforme mencionado acima as informações são trocadas entre o INITIATOR e o TARGET de forma assíncrona, significando um ou dois bytes por vez (dependendo da largura do barramento), envoltos por “handshakes” compostos pelos sinais de “REQ/ACK”, e com o sentido da comunicação identificado pelo sinal “I/O”, sendo “true” a transferência do TARGET para o INITIATOR, e “false” a transferência em sentido contrário.
O protocolo SCSI define que as comunicações de comandos sejam feitas através de um “COMMAND DESCRIPTOR BLOCK – CDB”, o qual sempre começa com o primeiro BYTE do comando (OP.CODE), seguido pela identificação da unidade lógica (LUN), uma lista de parâmetros para o comando, e terminando com um BYTE de controle. Os bits 5-7 dos OP.CODES identificam o grupo ao qual o comando pertence, e os restantes bits 0-4 identificam o comando em si, dentro do grupo. Os grupos variam em tipo e comprimentos de comando (grupo 0 – comandos de seis bytes, grupo 1 – comandos de 10 bytes, grupo 5 – comandos de 12 bytes, etc).
O CDB também especifica o tamanho da transmissão de dados a ser efetuada. Comandos que usam 1 BYTE como indicador de comprimento permitem a transmissão de até 256 bytes de dados (comprimento = 0 significando 256 bytes). Já comandos que utilizam múltiplos bytes para essa indicação permitem até 65535 bytes em uma única operação. Neste caso, a especificação de “length” = 0 indica que nenhum byte será enviado.
Ao final da operação, o TARGET deve retornar ao INITIATOR uma indicação de STATUS, que informa como foi o andamento da operação. As indicações do STATUS BYTE são : GOOD (operação OK), CHECK CONDITION (ocorrência de erros), BUSY (resposta à tentativa de inicio de operação por um INITIATOR, enquanto o TARGET ainda esta processando um comando anterior) e RESERVATION CONFLICT (conflito de RESERVE/RELEASE em uma LUN ou EXTENT).
Durante a execução de um comando, o TARGET pode decidir que irá precisar de um tempo adicional para obter os dados (uma operação de READ, por exemplo, que implique antes em um SEEK), e desconetar-se do INITIATOR, permitindo assim uma melhor utilização do barramento.
Um ponto importante a ser ressaltado aqui é que, em linhas gerais, este protocolo implementa um esquema de prioridades que deve ser levado em conta durante a implementação de um subsistema que o utilize. Os discos físicos de prioridade mais alta (SCSI-ID mais alto) sempre ganharão acesso ao barramento ANTES dos outros. Isto, quando bem utilizado, pode trazer vantagens substanciais ao ambiente como um todo.
Algumas implementações de protocolo SCSI acrescentam uma funcionalidade conhecida geralmente como “FAIRNESS SUPPORT”. Em linhas gerais, esta função impede que um TARGET inicie a arbitragem antes que todos os outros tenham tido sua chance para fazê-lo, diminuindo o impacto causado aos discos de menor prioridade (SCSI-ID mais baixo).
|
Dica 4 – Certifique-se que os discos de mais alta prioridade de seu subsistema sejam ocupados por dados de ambientes transacionais, reservando os últimos ao processamento batch concorrente. Este esquema assemelha-se ao antigamente utilizado nas prioridades de CPU, conhecidos como MTW (Mean Time to Wait), no qual workloads rápidos e I/O bound são beneficiados. Esta dica só é válida para SCSIs sem FAIRNESS SUPPORT. |
Fibre Channel é tanto um padrão de comunicação (cabeamentos e conexões), quanto um protocolo de transporte aberto, conforme definido por normas ANSI (Comitê X3T11) e que pode ser implementado tanto em fibras óticas quanto em fiações de cobre, sendo portanto, um padrão para meios físicos de comunicação. Este padrão é amplamente utilizado na conectividade física do que é conhecido hoje com “SANs – Storage Area Networks”, ou seja, redes especializadas na interconexão de dispositivos de armazenamento a servidores. A palavra “FIBRE” foi criada pelo comitê quando o uso de fiações de cobre foi introduzida no padrão. Originalmente, referia-se somente a fibras óticas.
Fibre Channel Aribtrated Loop ou FC-AL é uma das topologias implementadas pelas normas FIBRE (sendo as outras a POINT-TO-POINT e o FIBRE CHANNEL SWITCHED FABRIC, ou FC-SW). Todas estas topologias são utilizadas para interconectar dispositivos de armazenamento a seus servidores, em plataformas baixas. Não necessitando de sobrecargas adicionais, como as geradas por seleção de rotas em ambientes FC-SW (como o FSPF-Fabric shortest path first, por exemplo) e ainda atendendo a um grande número de dispositivos, é a topologia deste tipo em uso na maior parte dos subsistemas de armazenamento para MainFrame atualmente. Uma exceção seriam os novos DS´s da IBM, que conectam os discos através de pares de switches fabric, característicos do FC-SW.
Baseado nos padrões Fibre, o FC-AL também utiliza o conceito de ports (o que pode, neste caso, ser entendido como “portas”), utilizando as “L”-ports, como a L-port, NL-port (nódulo port com capacidade de loop), FL-port (fabric port com capacidade de loop), etc. Nesta topologia, até 126 nódulos (L ou NL ports) podem ser interconectados por uma rede, a qual é gerenciada como um barramento compartilhado, no qual os dados fluem em uma única direção de cada vez, transmitindo dados e primitivas (nome dado ao protocolo de troca de informações de comando e controle), a 100 ou 200 MB/S, dependendo do loop ser baseado em uma rede de 1, 2 ou 4 Gb/S.
Uma vez conectados fisicamente, os dispositivos participantes de uma rede FC-AL iniciam o que é chamado de LIP (Loop Initialization Primitive), durante o qual os mesmos são identificados e, opcionalmente, recebem um mapa de seu posicionamento no loop. Após o LIP, a rede entra em um estado de gerenciamento, controlado pelo dispositivo de mais baixo endereço físico, o qual foi identificado por uma outra primitiva, chamada LISM (Loop Initialization Select Master). No caso dos subsistemas de grande porte, esta função cabe à placa adaptadora.
Após terem sido executadas as primitivas de inicialização, qualquer dispositivo que queira iniciar uma conexão terá, a semelhança do padrão SCSI, que arbitrar. Caso haja mais de um dispositivo tentando a arbitragem ao mesmo tempo, o que tiver o menor endereço físico (AL-PA – Arbitrated Loop Physical Address) vence, ganhando controle sobre o loop, e podendo estabelecer uma conexão com outro nódulo e utilizar, durante este tempo, toda a largura de banda disponível para sua transmissão. A maior parte das implementações FC-AL conta com o FAIRNESS ALGORITHM, o que impede que dispositivos de mais alta prioridade (menor AL-PA) possam monopolizar a conexão física.
O endereçamento neste ambiente é feito através de endereços de port de 24 bits, dos quais o último byte é adquirido durante a execução do LIP, identificando o dispositivo para a rede. Este esquema é o escolhido para redes FC pois a alternativa de 64 bits utilizada no endereçamento via WWN (World Wide Name) força a utilização de cabeçalhos maiores de roteamento, e conseqüentemente, maiores tempos de transmissão. Dos 24 bits utilizados no que é chamado de 24-bit Port Addressing Scheme, os bits (23-16) designam o domínio, (15-8) identificam a área e os restantes (7-0) o port, correspondendo ao endereço físico da porta no loop para o qual esta se identificou.
Uma vez estabelecida a conexão, os dados são transmitidos em unidades de 2112 bytes de cada vez, o que é conhecido como FIBRE CHANNEL FRAME, utilizando-se o que foi padronizado como Classe 1 de serviços do padrão FC-PH (para esta classe, uma conexão dedicada é estabelecida entre origem e destino durante o período de transmissão dos dados e primitivas). O maior tamanho de dados transmitidos a cada operação é definido pelas primitivas de inicialização, variando entre os subsistemas.
Das 3 formas de conexão apresentadas até agora, a SSA é a que mais se distingue das outras, tanto física quanto logicamente. Mesmo tendo a capacidade de mapear protocolos anteriores (SCSI-2), suas formas de conexão e controles tornam-na bem diferente das demais, sendo atualmente utilizada somente no IBM Enterprise Storage Server (ESS Shark), dentre os subsistemas que atendem a plataforma MainFrame.
Sua forma mais comum de implementação é a de um loop, com 2 conexões físicas de leitura e 2 de gravação, o que permite até 4 operações simultâneas, sendo 2 em cada direção do loop. Isso é possível porque diferentemente das arquiteturas que compartilham o meio físico de transmissão, na SSA cada participante conecta-se diretamente a seu “vizinho”, tendo 2 caminhos (um para leitura e um para gravação) para cada um. Desta forma, os dados que saem da placa adaptadora para um determinado disco são transmitidos de disco a disco, até chegarem em seu destino.
Caso haja, por exemplo, 8 discos em um loop, e uma gravação esteja sendo efetuada no terceiro, isso deixa o caminho livre entre o retorno do loop e os outros 5 discos, permitindo uma outra operação simultânea de gravação aconteça.
A figura abaixo exemplifica a operação de um nódulo SSA :
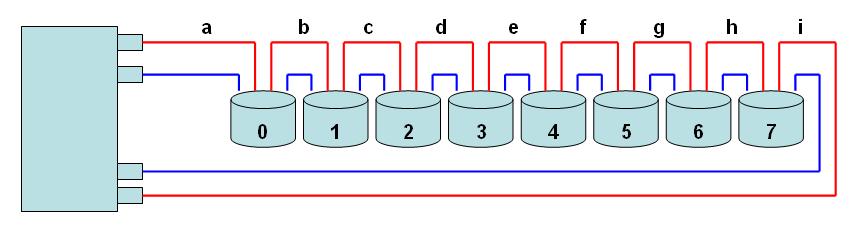
Figura 6 – SSA Loop : Se uma gravação estiver acontecendo entre a placa adaptadora e o disco físico 2, os trechos a-b-c do link em vermelho estarão ocupados. Entretanto, uma outra gravação pode ocorrer simultaneamente com o disco 4, seguindo a rota i-h-g-f, que estava livre. A mesma lógica vale para operações de leitura. Desta forma, até 4 operações (2 leituras e 2 gravações), podem acontecer ao mesmo tempo em um único loop. As placas adaptadoras SSA160 são compostas por 2 nódulos SSA de 40 MB/S em cada link.
Nessa arquitetura, o conceito de arbitragem é substituído pelo uso de senhas (“tokens”), chamados de SAT e SAT´, um para cada sentido do loop, que circulam entre os dispositivos participantes. Quem tiver o SAT ou o SAT´ dará preferência ao envio de seus próprios frames à retransmissão dos frames de outros, ocorrendo o contrário aos dispositivos que não o tiverem naquele momento. A titulo de curiosidade, o nome “SAT” vem de “SATisfy yourself”, significando que quem estiver de posse da senha pode satisfazer sua necessidade de envio ou recebimento de dados naquele momento.
Apesar da banda nominal de cada link SSA ser de 40 MB/S, 20% da mesma é utilizada por uma forma de codificação de dados chamada de 8b/10b, na qual cada byte (8 bits de dados) é codificado na forma de 10 bits pela inserção de controles e sua substituição por valores especificados em tabela para cada byte. Isso é feito para atender necessidades de hardware, como por exemplo garantir a reconstrução do sinal de “clock” a partir dos dados enviados, o que seria difícil com vários bits de mesma polaridade sendo transmitidos juntos, e a correção de um fenômeno chamado de “dc bias” que tende a surgir nesta mesma situação, dificultando a detecção da diferença de sinal entre 0´s e 1´s.
Cada frame SSA é composto por até 128 bytes de dados, acrescentados de cabeçalhos (com especificações do conteúdo do frame e o endereço do destinatário, chamado de UID), e verificações de erro CRC ao final.
Uma outra forma de conexão possibilitada por esta arquitetura insere uma outra placa adaptadora ao final de cada loop, ao invés de fechá-lo de volta na placa original. Esta forma é a utilizada no IBM-ESS e permite que cada placa defina seu domínio (grupos de discos), fazendo com que as transmissões de uma controladora não interfiram com as da outra. Ainda nesta forma de conexão, cada placa adaptadora liga-se a uma dos clusters do ESS durante operação normal, permitindo ainda que assuma o restante do loop, caso a outra placa ou seu cluster venha a falhar.
![]()
![]()
![]()
![]()